Thanks to everyone who participated in our recent webinar on how to load balance MySQL and MariaDB with ClusterControl and ProxySQL!
This joint webinar with ProxySQL creator René Cannaò generated a lot of interest … and a lot of questions!
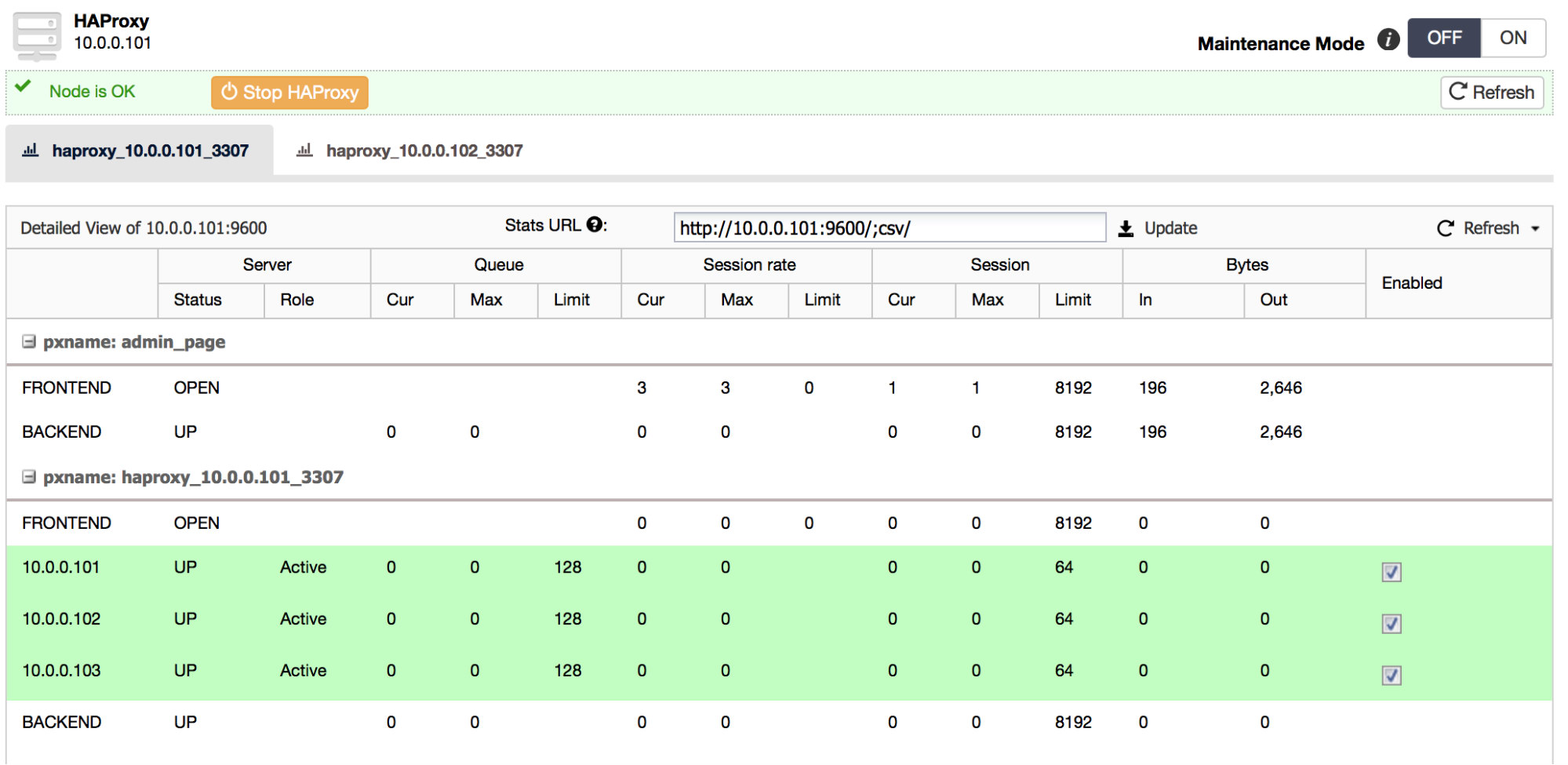
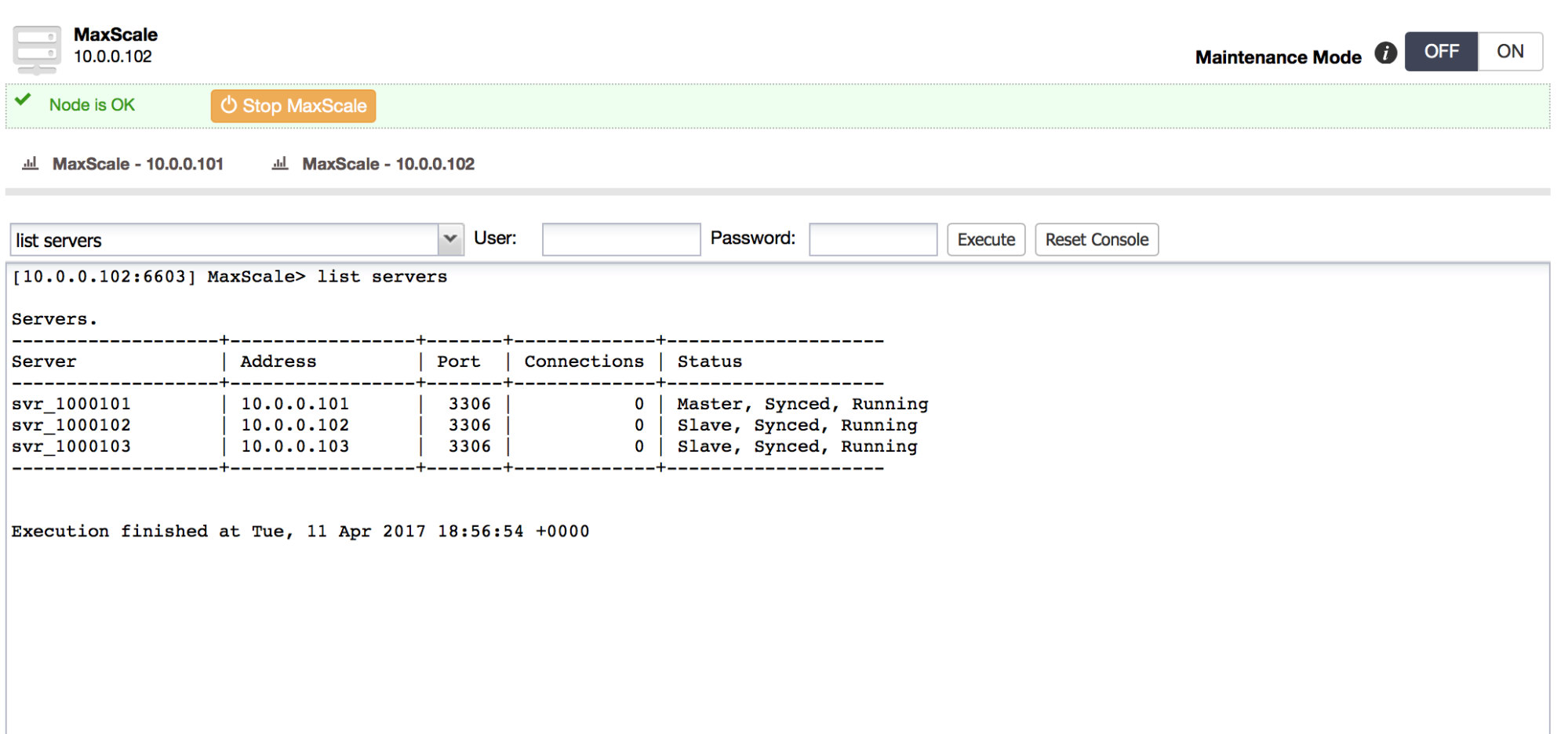
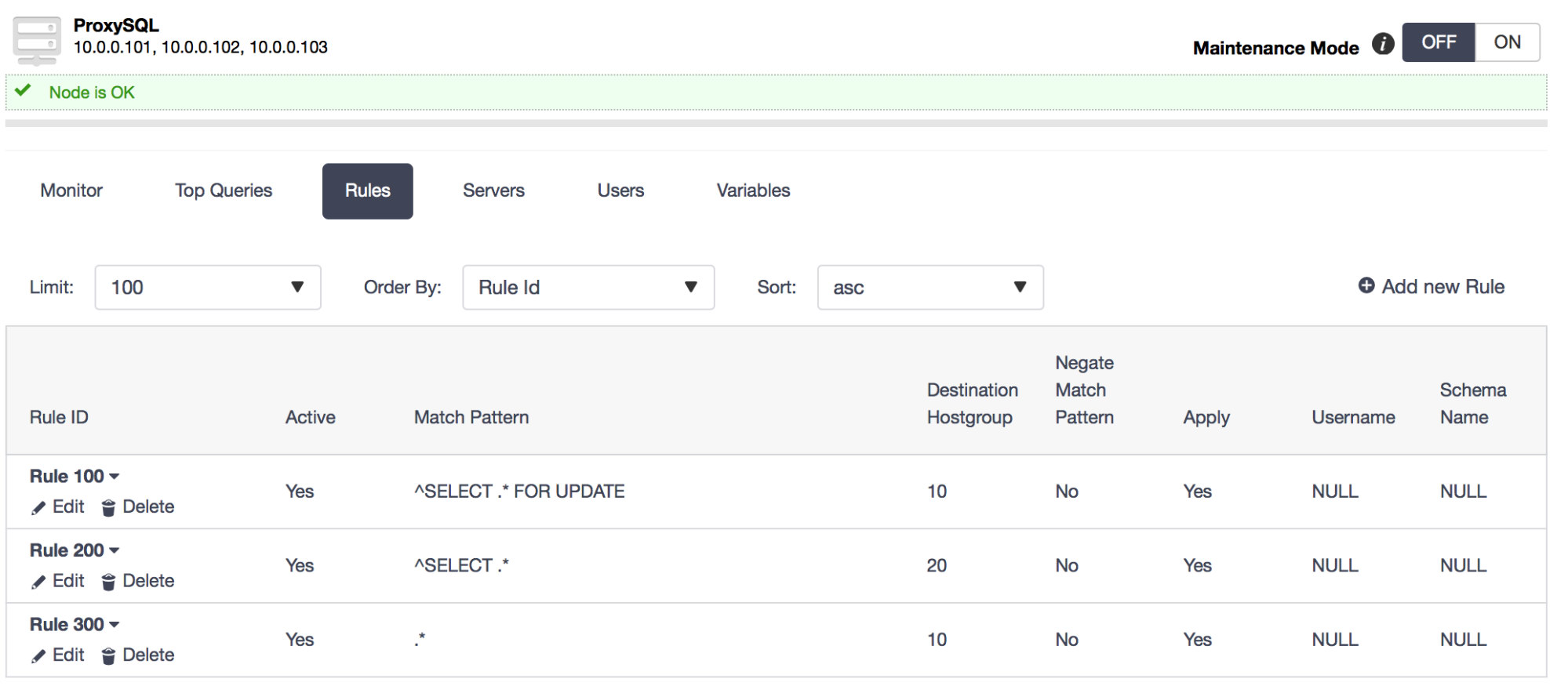
We covered topics such as ProxySQL concepts (with hostgroups, query rules, connection multiplexing and configuration management), went through a live demo of a ProxySQL setup in ClusterControl (try it free) and discussed upcoming ClusterControl features for ProxySQL.
These topics triggered a lot of related questions, to which you can find our answers below.
If you missed the webinar, would like to watch it again or browse through the slides, it is available for viewing online.
You can also join us for our follow-up webinar next week on Tuesday, April 4th 2017. We’re again joined by René and will be discussing High Availability in ProxySQL.
Sign up for the webinar on HA in ProxySQL
Webinar Questions & Answers
Q. Thank you for your presentation. I have a question about connection multiplexing: does ProxySQL ensure that all statements from start transaction to commit are sent through the same backend connection?
A. This is configurable.
A small preface first: at any time, each client’s session can have one or more backend connections associated with it. A backend connection is associated to a client when a query needs to be executed, and normally it returns immediately back to the connection pool. “Normally” means that there are circumstances when this doesn’t happen. For example, when a transaction starts, the connection is not returned anymore to the connection pool until the transaction completes (either commits or rollbacks). This means that all the queries that should be routed to the same hostgroup where the transaction is running, are guaranteed to run in the same connection.
Nonetheless, by default, a transaction doesn’t disable query routing. That means that while a transaction is running on one connection to a specific hostgroup and this connection is associated with only that client, if the client sends a query destinated to another hostgroup, that query could be sent to a different connection.
Whatever the query could be sent to a different connection or not based on query rules is configurable by the value of mysql_users.transaction_persistent:
- 0 = queries for different hostgroup can be routed to different connections while a transaction is running;
- 1 = query routing will be disabled while the transaction is running.
The behaviour is configurable because it depends on the application. Some applications require that all the queries are part of the same transaction, other applications don’t.
Q. What is the best way to set up a ProxySQL cluster? The main concern here is configuration of the ProxySQL cascading throughout the cluster.
A. ProxySQL can be deployed in numerous ways.
One typical deployment pattern is to deploy a ProxySQL instance on every application host. The application would then connect to the proxy using very low latency connection via Unix socket. If the number of application hosts increase, you can deploy a middle-layer of 3-5 ProxySQL instances and configure all ProxySQL instances from application servers to connect via this middle-layer. Configuration management, typically, would be handled using Puppet/Chef/Ansible infrastructure orchestration tools. You can also easily use home-grown scripts as ProxySQL’s admin interface is accessible via MySQL command line and ProxySQL reconfiguration can be done by issuing a couple of SQL statements.
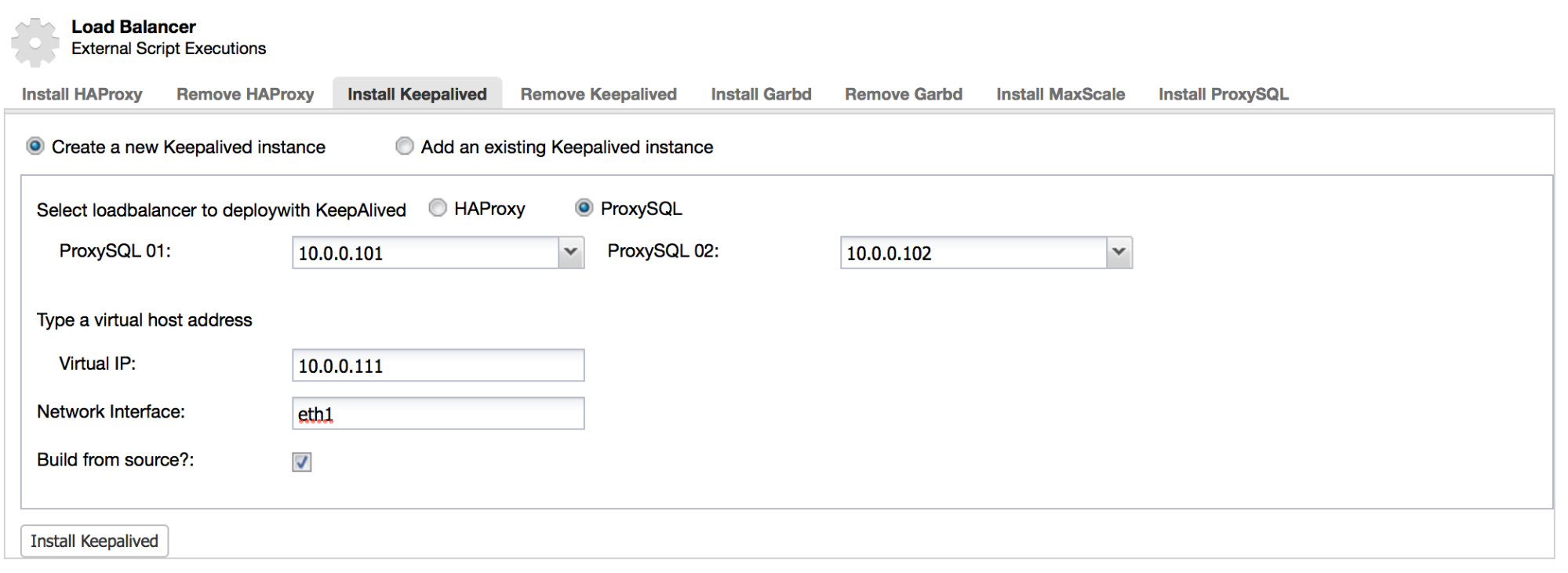
Q. How would you recommend to make the ProxySQL layer itself highly available?
There are numerous methods to achieve this.
One common method is to deploy a ProxySQL instance on every application host. The application would then connect to the proxy using very low latency connection via Unix socket. In such a deployment there is no single point of failure as every application host connects to the ProxySQL installed locally.
When you implement a middle-layer, you will also maintain HA as 3-5 ProxySQL nodes would be enough to make sure that at least some of them are available for local proxies from application hosts.
Another common method of deploying a highly available ProxySQL setup is to use tools like keepalived along with virtual IP. The application will connect to VIP and this IP will be moved from one ProxySQL instance to another if keepalived detects that something happened to the “main” ProxySQL.
Q. How can ProxySQL use the right hostgroup for each query?
A. ProxySQL route queries to hostgroups is based on query rules - it is up to the user to build a set of rules which make sense in their environment.
Q. Can you tell us more about query mirroring?
A. In general, the implementation of query mirroring in ProxySQL allows you to send traffic to two hostgroups.
Traffic sent to the “main” hostgroup is ensured to reach it (unless there are no hosts in that hostgroup); on the other hand, mirror hostgroup will receive traffic on a “best effort” basis - it should but it is not guaranteed that the query will indeed reach the mirrored hostgroup.
This limits the usefulness of mirroring as a method to replicate data. It is still an amazing way to do load testing of new hardware or redesigned schema. Of course, mirroring reduces the maximal throughput of the proxy - queries have to be executed twice so the load is also twice as high. The load is not split between the two, but duplicated.
Q. And what about query caching?
Query cache in ProxySQL is implemented as a simple key->value memory store with Time To Live for every entry. What will be cached and for how long - this is decided on the query rules level. The user can define a query rule matching a particular query or a wider spectrum of them. To identify query results set in cache, ProxySQL uses query hash along with information about user and schema.
How to set TTL for a query? The simplest answer is: to the maximum value of replication lag which is acceptable for this query. If you are ok to read stale data from slave, which is lagging 10 seconds, you should be fine reading stale data from cache when TTL is set to 10000 milliseconds.
Q. Connection limit to backends?
A. ProxySQL indeed implements a connection limit to backend servers. The maximum number of connections to any backend instance is defined in mysql_servers table.
Because the same backend server can be present in multiple hostgroups, it is possible to define the maximum number of connections per server per hostgroup.
This is useful for example in the case of a small set of connections where specific long running queries are queued without affecting the rest of the traffic destinated to the same server.
Q. Regarding the connection limit from the APP: are connections QUEUED?
A. If you reach the mysql-max_connections, further connections will be rejected with the error “Too many connections”.
It is important to remember that there is not a one-to-one mapping between application connections and backend connections.
That means that:
- Access to the backends can be queued, but connections from the application are either accepted or rejected.
- A large number of application connections can use a small number of backend connections.
Q. I haven’t heard of SHUN before: what does it mean?
A. SHUN means that the backend is temporarily marked as non-available but ProxySQL will attempt to connect to it after mysql-shun_recovery_time_sec seconds
Q. Is query sharding available across slaves?
A. Depending on the meaning of sharding, ProxySQL can be used to perform sharding across slaves. For example, it is possible to send all traffic for a specific set of tables to a set of slaves (in a hostgroup). Splitting the slaves into multiple hostgroups and performing query sharding accordingly is possible to improve performance, as each slave won’t read from disk data from tables for which it doesn’t process any query.
Q. How do you sync the configuration of ProxySQL when you have many instances for H.A ?
A. Configuration management, typically, would be handled using Puppet/Chef/Ansible infrastructure orchestration tools. You can also easily use home-grown scripts as ProxySQL’s admin interface is accessible via MySQL command line and ProxySQL reconfiguration can be done by issuing a couple of SQL statements.
Q. How flexible or feasible it is to change the ProxySQL config online, eg. if one database slave is down, how is that handled in such a scenario ?
A. ProxySQL configuration can be changed at any time; it’s been designed with such level of flexibility in mind.
‘Database down’ can be handled differently, it depends on how ProxySQL is configured. If you happen to rely on replication hostgroups to define writer and reader hostgroups (this is how ClusterControl deploys ProxySQL), ProxySQL will monitor state of read_only variable on both reader and writer hostgroups and it will move hosts as needed.
If master is promoted by external tools (like ClusterControl, for example), read_only values will change and ProxySQL will detect a topology change and it will act accordingly. For a standard “slave down” scenario there is no required action from the management system standpoint - without any changes in read_only value ProxySQL will just detect that the host is not available and it will stop sending queries to it, re-executing on other members of the hostgroup those queries which didn’t complete on dead slave.
If we are talking about a setup not using replication hostgroups then it is up to the user and their scripts/tools to implement some sort of logic and reconfigure ProxySQL on runtime using admin interface. Slave down, though, most likely wouldn’t require any changes.
Q. Is it somehow possible to SELECT data from one host group into another host group?
A. No, at this point it is not possible to execute cross-hostgroup queries.
Q. What would be RAM/Disk requirements for logs , etc?
A. It basically depends on the amount of log entries and how ProxySQL log is verbose in your environment. Typically it’s neglectable.
Q. Instead of installing ProxySQL on all application servers, could you put a ProxySQL cluster behind a standard load balancer?
A. We see no reason why not? You can put whatever you like in front of the ProxySQL - F5, another layer of software proxies - it is up to you. Please keep in mind, though, that every layer of proxies or load balancers adds latency to your network and, as a result, to your queries.
Q. Can you please comment on Reverse Proxy, whether it can be used in SQL or not?
A. ProxySQL is a Reverse Proxy. Contrary to a Forward Proxy (that acts as an intermediary that simply forwards requests), a Reverse Proxy processes clients’ requests and retrieves data from servers. ProxySQL is a Reverse Proxy: clients send requests to ProxySQL, that will understand the request, analyze it, and decide what to do: rewrite, cache, block, re-execute on failure, etc.
Q. Does the user authentication layer work with non-local database accounts, e.g. with the pam modules available for proxying LDAP users to local users?
A. There is no direct support for LDAP integration but, as configuration management in ProxySQL is a child’s play, it is really simple to put together a script which will pull the user details from LDAP and load them into ProxySQL. You can use cron to sync it often. All ProxySQL needs is a username and password hash in MySQL format - this is enough to add a user to ProxySQL.
Q. It seems like the prescribed production deployment includes many proxies - are there any suggestions or upcoming work to address how to make configuration changes across all proxies in a consistent manner?
A. At this point it is recommended to leverage configuration management tools like Chef/Ansible/Puppet to manage ProxySQL’s configuration.
You can also join us for our follow-up webinar next week on Tuesday, April 4th 2017. We’re again joined by René and will be discussing High Availability in ProxySQL.